[Debezium] 쿠버네티스 내 PostgreSQL Source Connector 구현
이번 글은 Debezium의 Source Connector와 Postgresql의 Logical Replication을 활용하여, 데이터베이스의 2개 테이블을Kafka로 복제하는 내용을 다뤄볼 것이다.
Kafka Connector로 크게 Source Connector와 Sink Connector가 있는데, Source Connector는 원천 데이터 소스를 카프카로 보내는 역할을, Sink Connector는 카프카에 저장된 데이터를 이관할 플랫폼으로 전송하는 역할을 한다.

위 사진에서 카프카를 기준으로 Data Source -> Kafka까지의 역할이 Source Connector의 역할이다.
https://debezium.io/documentation/reference/3.0/connectors/postgresql.html
Debezium connector for PostgreSQL :: Debezium Documentation
Tombstone events When a row is deleted, the delete event value still works with log compaction, because Kafka can remove all earlier messages that have that same key. However, for Kafka to remove all messages that have that same key, the message value must
debezium.io
공식 Docs를 보면 설명이 잘 되어 있는 편이고, 이를 참고하여 쿠버네티스 클러스터 내에서 Source Connector를 구현해 볼 것이다.
1. DB 생성
Postgresql의 파드를 만들어내는 Statefulset과 해당 NodePort, Headless 서비스를 간단하게 만들었다.
외부에서는 32222 포트로 접속이 가능하고 내부에서 호출을 위하여 headless 서비스를 분리시켜 놓았다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: test-db
spec:
serviceName: test-db-service
replicas: 1
selector:
matchLabels:
app: test-db-app
template:
metadata:
labels:
app: test-db-app
spec:
containers:
- name: test-db-container
image: postgres:16.1
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: test
- name: POSTGRES_USER
value: user
- name: POSTGRES_PASSWORD
value: "1234"
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
volumeMounts:
- name: db-volume
mountPath: /var/lib/postgresql/data
volumes:
- name: db-volume
hostPath:
path: /mnt/test/test-pgdata
type: DirectoryOrCreate
---
apiVersion: v1
kind: Service
metadata:
name: test-db-service
labels:
app: test-db-app
spec:
ports:
- port: 5432
clusterIP: None
selector:
app: test-db-app
---
apiVersion: v1
kind: Service
metadata:
name: test-db-node
labels:
app: test-db-app
spec:
ports:
- port: 5432
nodePort: 32222
type: NodePort
selector:
app: test-db-app
Database : test
User : user
Password : 1234
로 DB 접속 툴을 이용하여 접속하면 정상적으로 DB가 생성된 것을 볼 수 있다.

2. Debezium(Kafka Connector) 생성
Debezium의 파드를 만들어내는 Statefulset과 해당 NodePort 서비스를 간단하게 만들었다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: kafka-connect
name: kafka-connect
spec:
serviceName: kafka-connect-service
replicas: 1
selector:
matchLabels:
app: kafka-connect
template:
metadata:
labels:
app: kafka-connect
spec:
containers:
- name: kafka-connector
image: quay.io/debezium/connect:3.0.0.Final
imagePullPolicy: Always
env:
- name: LOG_LEVEL
value: ERROR
- name: BOOTSTRAP_SERVERS
value: <카프카 클러스터 주소>
- name: GROUP_ID
value: test-connector # 컨슈머 그룹 ID
- name: CONFIG_STORAGE_TOPIC
value: test_pipeline_config
- name: OFFSET_STORAGE_TOPIC
value: test_pipeline_offsets
- name: STATUS_STORAGE_TOPIC
value: test_pipeline_statuses
- name: CONFIG_STORAGE_REPLICATION_FACTOR
value: "3"
- name: OFFSET_STORAGE_REPLICATION_FACTOR
value: "3"
- name: STATUS_STORAGE_REPLICATION_FACTOR
value: "3"
ports:
- containerPort: 8083
name: kafka-connect
readinessProbe:
httpGet:
port: 8083
path: /connectors
initialDelaySeconds: 15
periodSeconds: 15
livenessProbe:
httpGet:
port: 8083
path: /connectors
initialDelaySeconds: 15
periodSeconds: 15
---
apiVersion: v1
kind: Service
metadata:
labels:
app: kafka-connect
name: kafka-connect
namespace: default
spec:
ports:
- nodePort: 32123
port: 8083
protocol: TCP
targetPort: 8083
selector:
app: kafka-connect
type: NodePort
Debezium을 구동 시키면 Kafka 클러스터에 연결을 하고, <CONFIG / OFFSET / STATUS>-STORAGE-TOPIC에 기입된 환경 변수대로 Topic을 생성하는데, 클러스터에 접속이 되지 않는다면 에러가 발생한다.
※ Debezium 버전에 따라서 Connector에서 지원하는 플랫폼이 차이가 있으니 참고
Debezium은 기본적인 기능들은 RestAPI로 지원하기 때문에 아래와 같이 Get을 날려보면 사진처럼 응답이 오는 것을 볼 수 있다.

그리고 Debezium이 생성되면서 만들어낸 Topic도 확인할 수 있다.
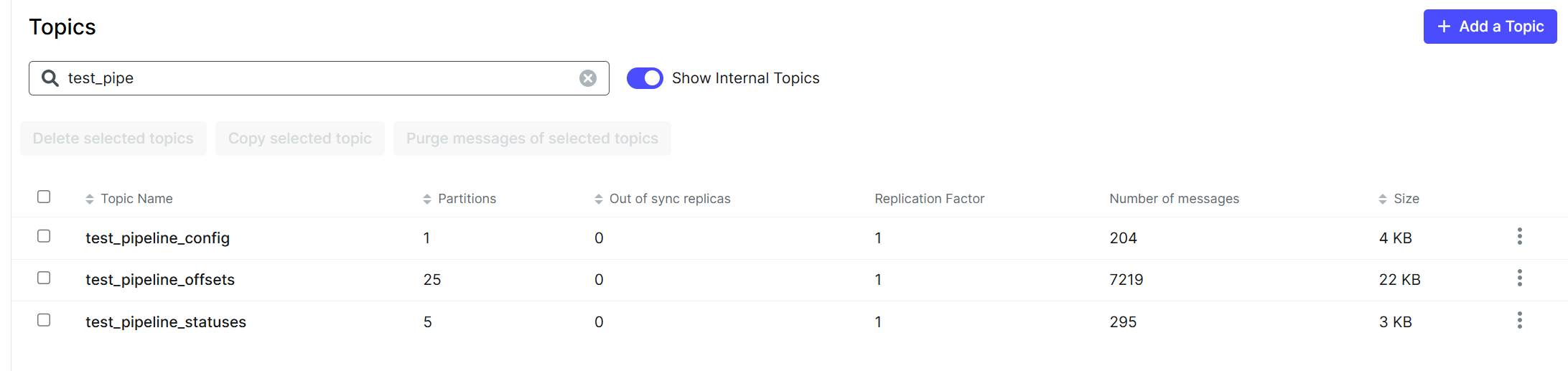
3. DB 옵션 변경
1번 단계에서 생성한 PostgreSQL의 wal_level은 기본적으로 주석으로 설정이 되어 있다.
postgresql.conf를 확인해 보면 아래와 같이 replica로 주석이 되어 있는 것을 볼 수 있다.
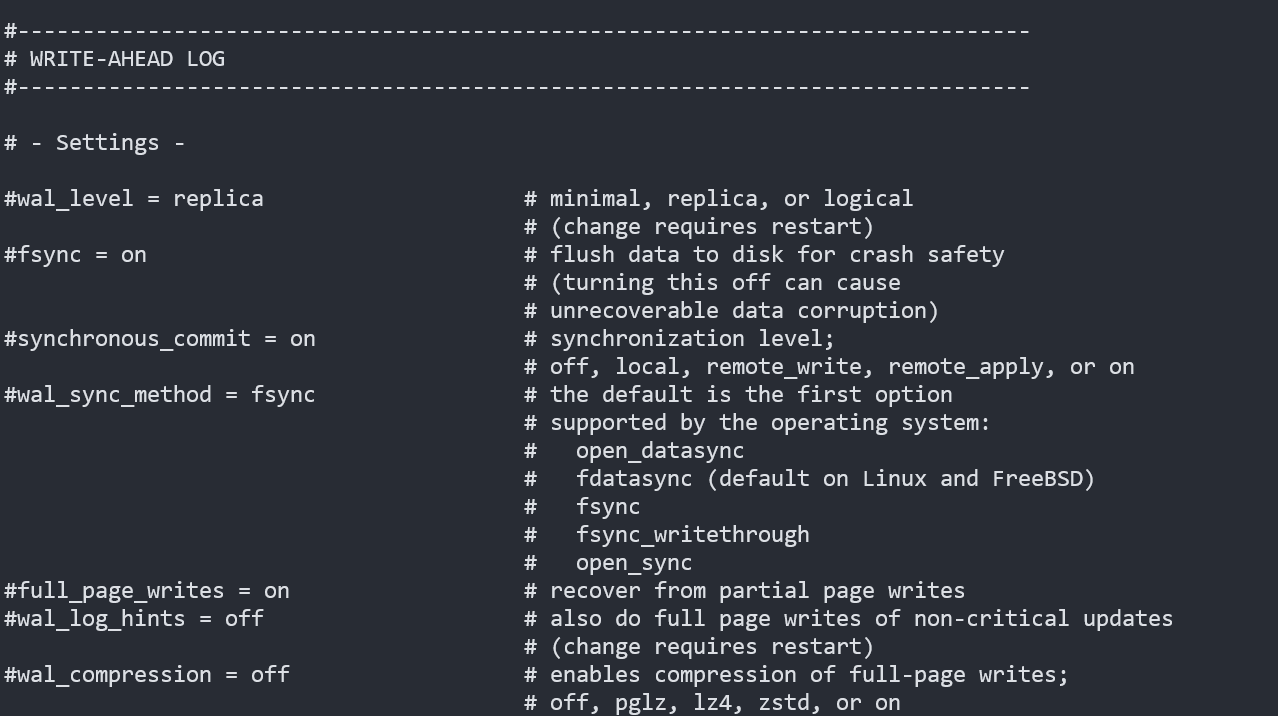
Debezium에서 PostgreSQL의 Source Connector는 기본적으로 wal_level을 logical로 사용하기에 변경이 필요하다.
이미지 : postgres:16.1
파일 위치(컨테이너 내부) : /var/lib/postgresql/data/pgdata/postgresql.conf
※ 해당 이미지에서는 docker exec나 kubectl exec으로는 파일을 수정할 수 없으니 이미지를 새로 제작하거나, 마운트 포인트에 Host로 접근하여 수정해야 한다.
※ 이미지 제작자에 따라 postgresql.conf의 위치가 각각 다르다.
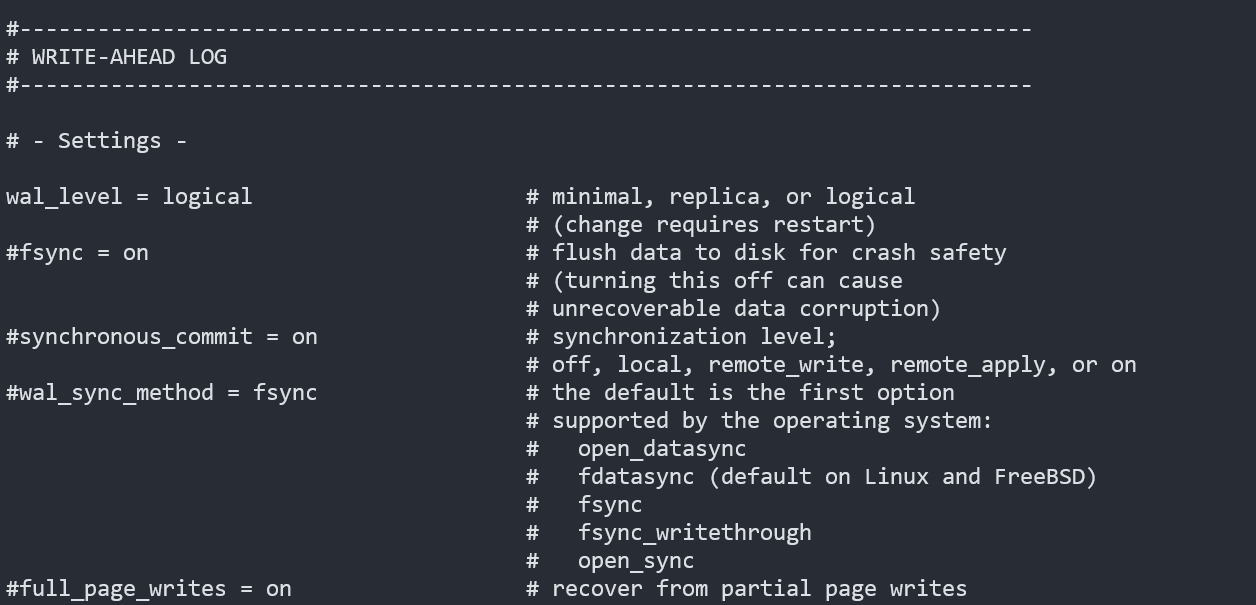
위와 같이 logical로 수정 후 저장하고, 컨테이너(파드)를 재시작하면 변경한 옵션이 적용된다.
4. Source DB에 테스트 테이블 및 테스트 데이터 입력
카프카로 이관할 데이터를 사전에 DB에 만들어 주는 과정이다.
이미 데이터가 있더라도 wal_level을 변경한 시점에 logical 기준으로 모든 데이터의 wal이 생성이 된다.
※ 데이터를 만드는 것과 옵션을 바꾸는 것의 순서는 상관이 없지만 wal 보존 주기 등 상세 옵션에 따라 차이가 존재한다.
4-1. 테이블 생성
-- 테스트 테이블 생성
CREATE TABLE test_table1
(
ID INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
txt1 VARCHAR(50) ,
txt2 VARCHAR(50) ,
txt3 VARCHAR(50)
);
CREATE TABLE test_table2
(
ID INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
txt1 VARCHAR(50) ,
txt2 VARCHAR(50) ,
txt3 VARCHAR(50)
);
4-2. 데이터 입력
-- 테스트 데이터 입력
do $$
begin
for i in 1..100 loop
INSERT INTO test_table1 ("txt1", "txt2", "txt3") VALUES (i,i+1,i+2);
end loop;
end;
$$;
commit;
do $$
begin
for i in 100..200 loop
INSERT INTO test_table2 ("txt1", "txt2", "txt3") VALUES (i,i+1,i+2);
end loop;
end;
$$;
commit;
위 SQL을 실행하면 아래와 같이 각 테이블에 데이터들이 잘 들어간 것을 볼 수 있다.
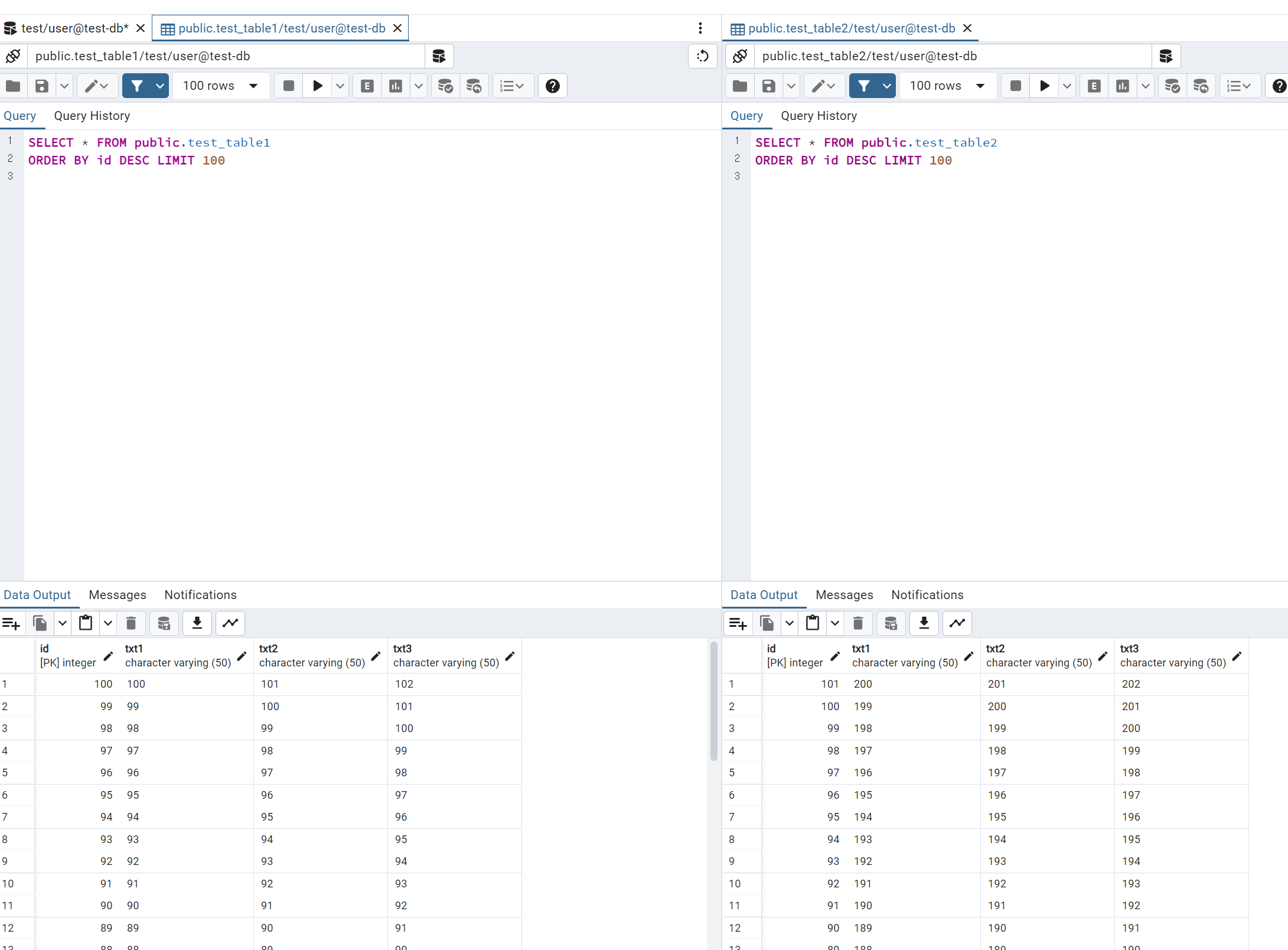
5. Debezium에 Source Connector 등록
테이블과 데이터를 생성했다면, 마지막으로 해당 데이터베이스에서 카프카로 이관할 커넥터를 만들면 끝이다.
이전에 Debezium에 대한 NodePort를 32123으로 주었으니, 해당 포트로 RestAPI를 이용하여 등록하면 끝이다.
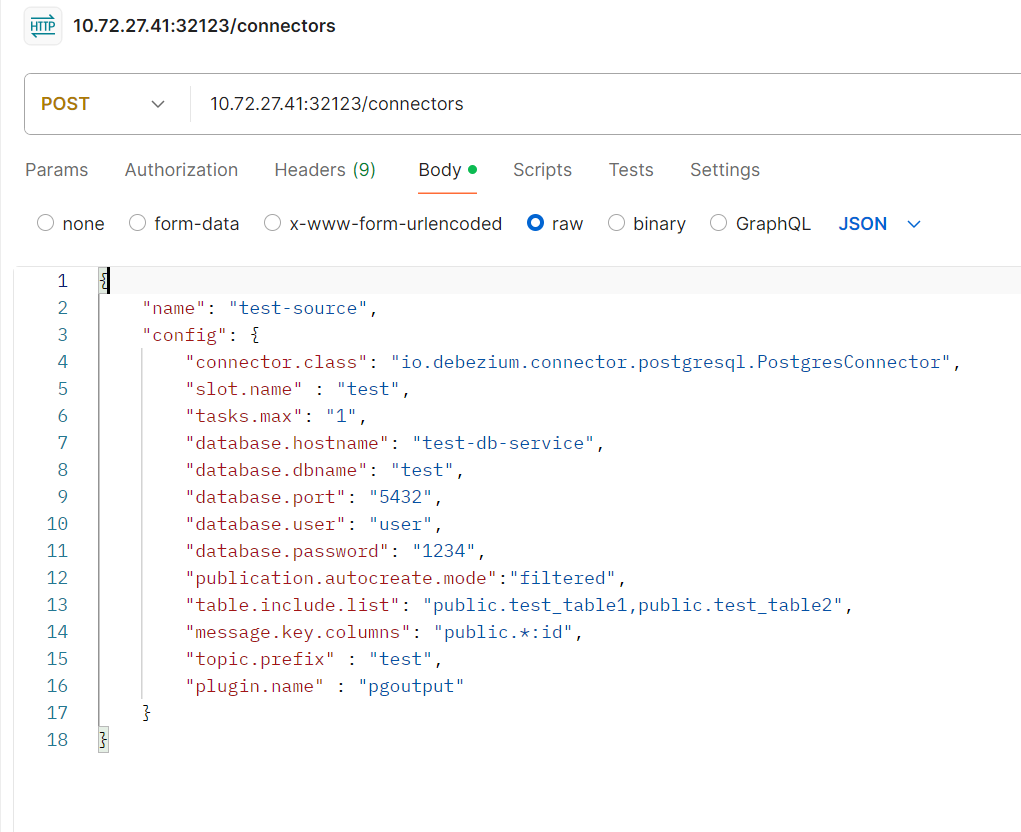
아래는 전송한 Json 양식이다.
{
"name": "test-source",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"slot.name" : "test",
"tasks.max": "1",
"database.hostname": "test-db-service",
"database.dbname": "test",
"database.port": "5432",
"database.user": "user",
"database.password": "1234",
"publication.autocreate.mode":"filtered",
"table.include.list": "public.test_table1,public.test_table2",
"message.key.columns": "public.*:id",
"topic.prefix" : "test",
"plugin.name" : "pgoutput"
}
}
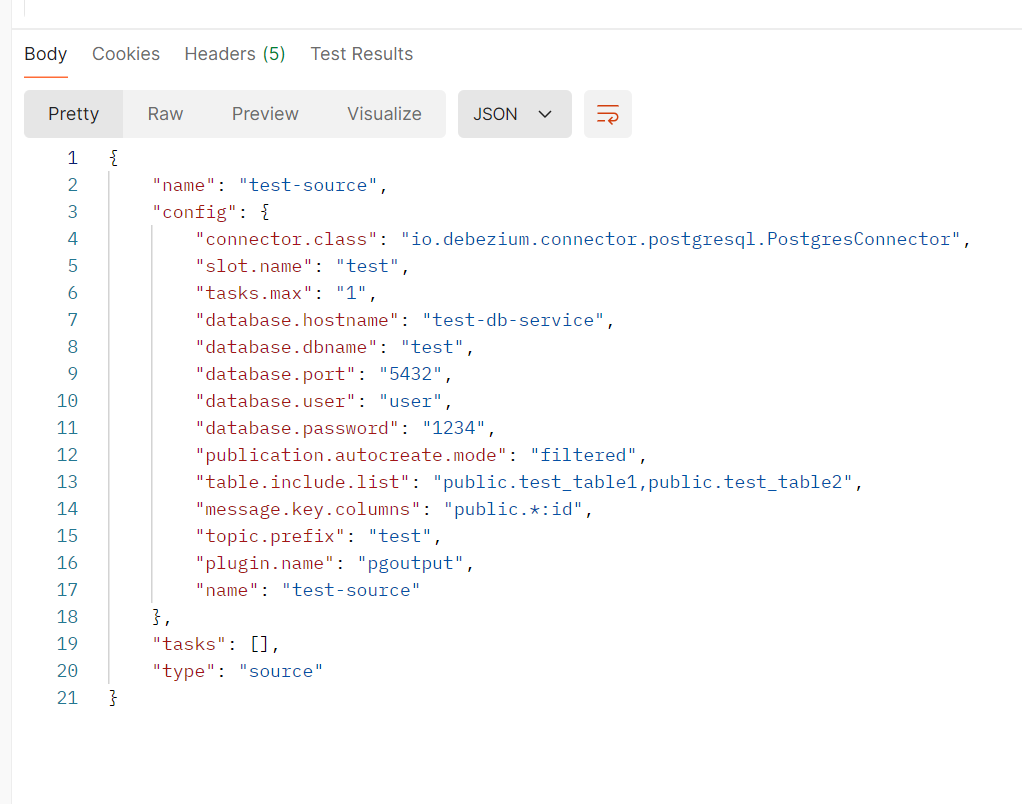
정상적으로 등록이 되면 유사한 내용으로 Response가 오는 것을 볼 수 있다.
https://debezium.io/documentation/reference/3.0/connectors/postgresql.html
Debezium connector for PostgreSQL :: Debezium Documentation
Tombstone events When a row is deleted, the delete event value still works with log compaction, because Kafka can remove all earlier messages that have that same key. However, for Kafka to remove all messages that have that same key, the message value must
debezium.io
위 Debezium 공식 사이트를 통하여 Json에 사용된 자세한 옵션들을 확인할 수 있다.
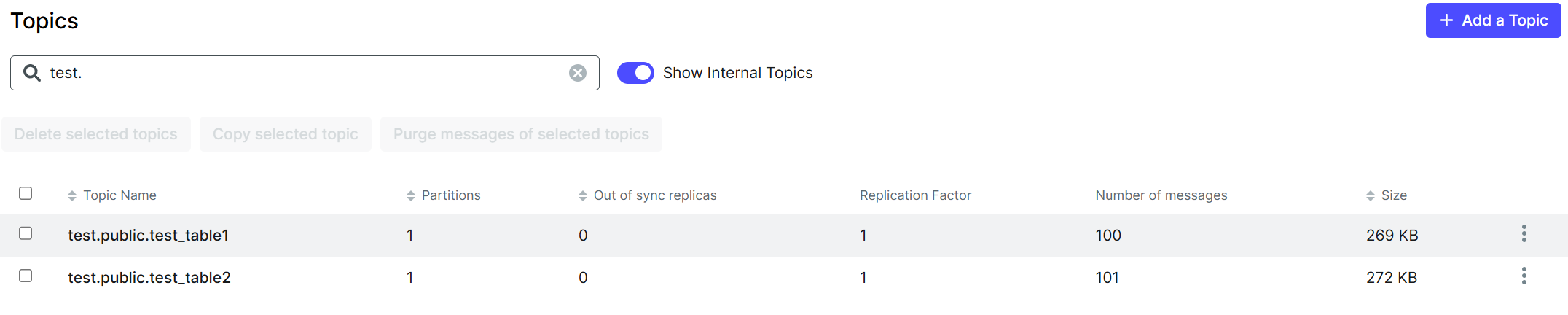
6. 카프카 내 데이터 확인
Source Connector까지 등록했으면, Json에 정의한 대로 Topic을 생성하고 Database에 있는 데이터를 카프카로 전송한 것을 확인할 수 있다.
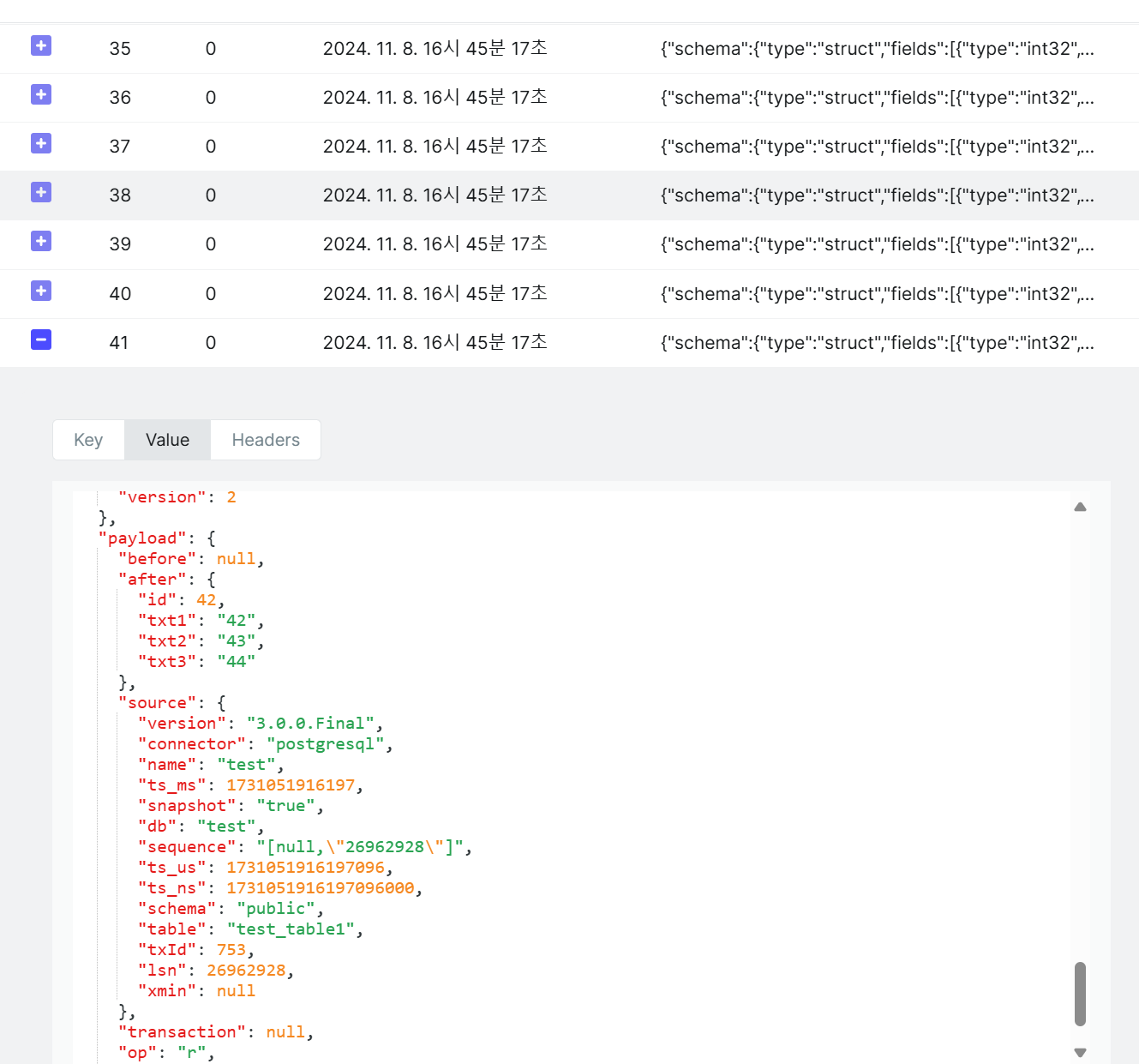
카프카에 저장된 데이터 형식은 Avro이고, 기존 생성한 id와 컬럼들을 제외하고도 많은 데이터가 같이 전송된 것을 볼 수 있다.
해당 과정들을 통하여, 별도의 애플리케이션 개발이 없이 데이터베이스 옵션 수정과 Json을 통한 Connector 등록으로 손쉽게 데이터베이스 내 데이터를 이벤트 브로커로 이관하는 방법을 알아보았다.
다음에는 이벤트 브로커에 저장된 데이터를 타 플랫폼으로 이관하는 Sink Connector에 대해 알아볼 것이다.