[Kafka] Kafka가 빠른 이유
kafka 홈페이지 : https://kafka.apache.org/
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
Apache Kafka는 최근 많은 회사에서 데이터 파이프라인의 중추적인 플랫폼으로 채택되어 이용되고 있다.
그 이유로는 많은 데이터를 신속하게 처리하는 성능, 폭넓은 확장성과 다양한 플러그인까지 지원하는것을 이유로 들 수 있다.
이번 글은 위 주제에서 카프카는 어떻게 신속하게 데이터를 처리할 수 있는지에 대하여 다뤄볼 것이다.
카프카는 공식 홈페이지에선 최저 2ms의 낮은 지연 대기 시간을 가진다고 소개하며, Confluent사의 자료를 토대로 하드웨어의 성능이 적절하게 충족할 때, 초당 처리량이 약 600Mb/s에 달한다고 한다.
참고자료 : https://developer.confluent.io/learn/kafka-performance/
Apache Kafka® Performance, Latency, Throughout, and Test Results
Benchmark Apache Kafka performance, throughput, and latency in a repeatable, automated way with OpenMessaging benchmarking on the latest cloud hardware.
developer.confluent.io
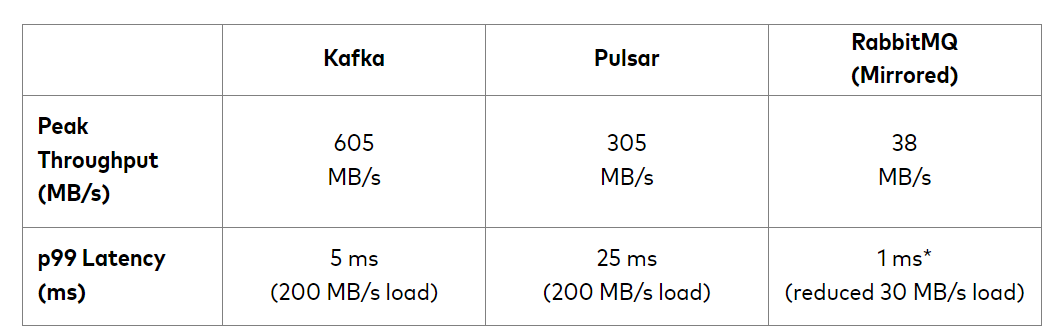
아래 자료는 Confluent 사에서 측정한 Kafka, Pulsar, RabbitMQ의 성능을 측정한 지표이다.
피크 타임의 카프카의 처리량이 제일 높고, RabbitMQ는 처리량이 상대적으로 매우 낮은 반면, 안정적인 Latency를 유지하는 것을 볼 수 있다.

이토록 처리량에 있어서 압도적으로 높은 성능을 보여주는 카프카는, 아래 두 가지의 기술을 기반으로 빠른 처리를 하도록 구현되었다.
1. Sequential I/O(순차 I/O)
데이터가 저장 장치에 저장될 때, 블록으로 구성되며 각 블록은 고유한 주소를 갖는다.
데이터를 읽거나 쓸 때(I/O) 블록 주소를 이용하게 되는데, Random Access로 I/O를 하게 된다면, 디스크 헤드가 무작위로 생성된 블록 주소로 이동하기 때문에, 읽기 및 쓰기 속도가 느려질 수 있다.
반면, Sequential Access I/O는 인접한 메모리 블록에서 데이터를 읽거나 쓰는 것을 의미하며, 디스크 헤드가 직선으로 움직일 수 있기 때문에, 효율적인 디스크 헤드 동선으로 Random Access I/O보다 속도가 빠르다.

아래는 저장소 타입과 방식에 따라서 성능이 얼마나 나오는지 나타낸 자료이다.
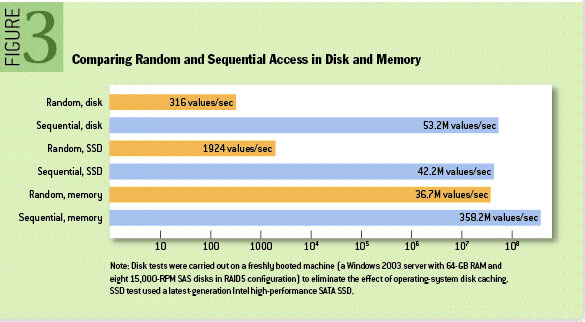
하드디스크에 Sequential Access I/O로 저장했을 때, 메모리 상에 Random Access I/O 하는 것과 필적한 성능을 보여준다는 것을 확인할 수 있다.
카프카는 이러한 Sequential Access I/O를 채택하여 I/O에 대한 성능을 높일 수 있었다.
2. Zero Copy
Zero Copy는 서로 다른 메모리 위치에 존재하는 데이터가 복사되는 횟수를 최소화하기 위하여 고안된 기술이다.
Kernel Buffer와 User Buffer사이에서 생겨나는 불필요한 데이터 복사와 Context-Switching을 줄여서 성능을 높였다.
Zero Copy를 구현하는 방법은 여러 있는데, 일반적으로 아래 3가지 단계를 통하여 Zero Copy를 구현할 수 있다.
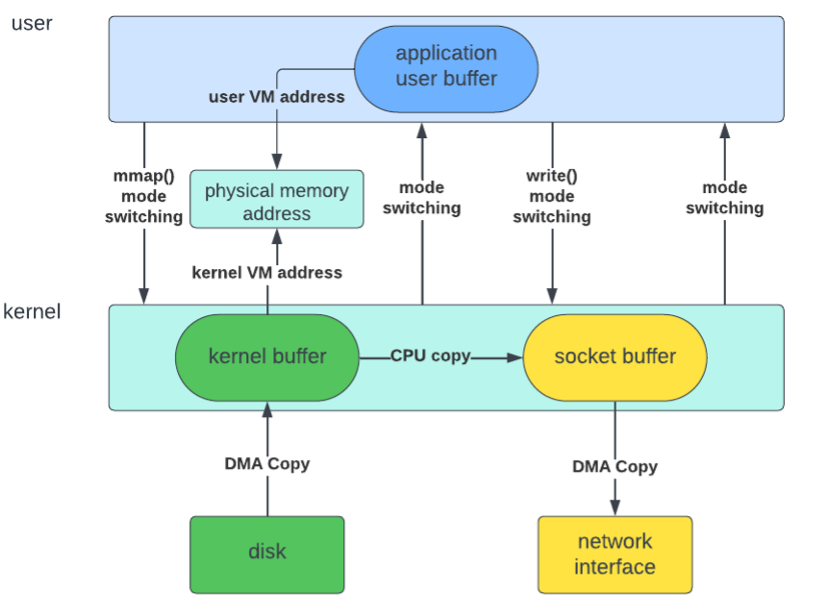
1. mmap() 사용(메모리 매핑): 사용자의 가상 메모리 주소를 커널 메모리 주소에 매핑하여 CPU의 불필요한 데이터 복사를 방지
2. sendfiles() 사용 : read() 및 write()를 대체하는 새로운 시스템 호출인 sendfile()을 이용하여, Context-Switching 절감
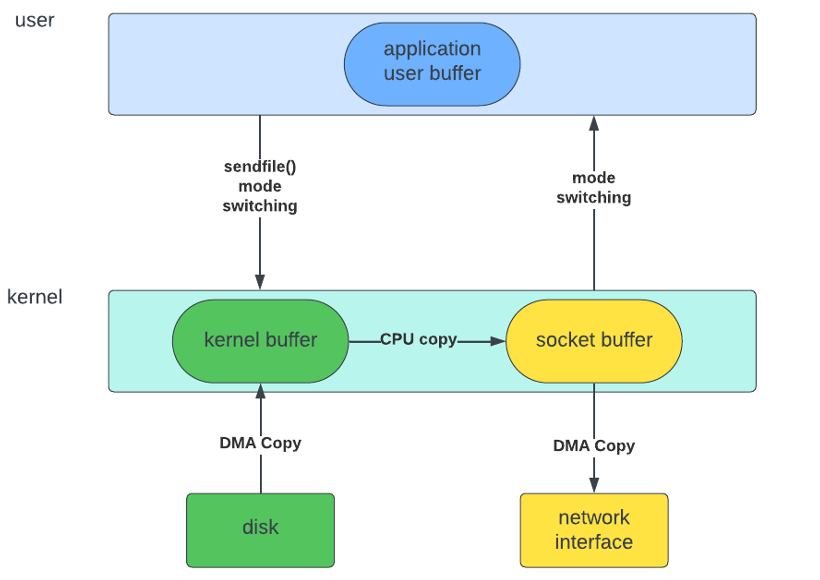
3. DMA Gather / Sendfile() 조합: DMA를 통해 디스크에서 커널 버퍼로 데이터를 복사하고, 소켓 버퍼에는 파일 설명자를 추가하여 이를 토대로 커널 버퍼에서 네트워크 인터페이스로 패킷을 만들어 네트워크 전송을 수행하여, 소켓 버퍼에 데이터가 복사하는 것을 절감
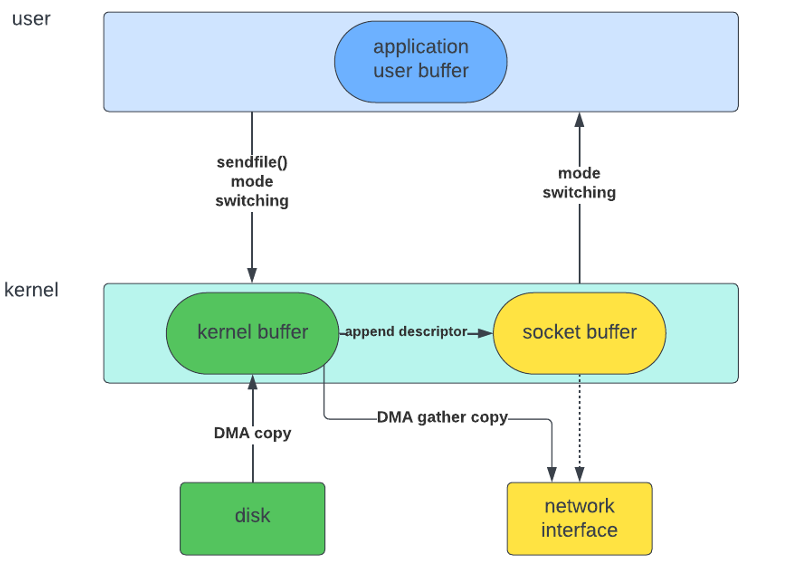
이러한 것들을 적용하여 카프카는 개발되었고, 깊은 기술적인 고민과 많은 노력을 통하여 높은 수준의 성능이 만들어졌다는 것을 알 수 있다.