[Kong] Kubernetes 환경 내 Prometheus의 Metric 수집 및 확인
쿠버네티스 클러스터에서 Ingress Controller로 Nginx나 Kong이 많이 이용된다.
여기서 Ingress(Gateway)를 통하여, 클러스터에 들어오는 트래픽과 Latency는 UX 개선에 참고할 수 있는 중요한 Metric이다.
해당 글을 통하여, Helm 차트로 설치한 Kong Proxy(Gateway)의 메트릭을 Prometheus를 이용하여 수집하고 Grafana 대시보드를 이용하여 확인하는 과정을 알아볼 것이다.
1. Helm values.yaml 수정
- admin 활성화

메트릭을 수집하기 위하여 kong admin을 활성화시켜 주고 http 이용을 위하여 활성화한다.
[Default에서 수정한 옵션]
admin.enabled : false -> true
admin.type: NodePort -> ClusterIP
admin.http.enabled : false -> true
※ 실제 메트릭은 kong admin에 해당하는 8001번(https : 8444) 포트, /metrics 경로에서 수집된다.
메트릭 확인

수정한 values.yaml로 kong을 배포하면, 위와 같은 서비스들이 생성된다.
이후 admin 서비스로 8001번 포트의 /metrics 경로를 호출하면, 아래와 같은 메트릭을 응답해 주는 것을 볼 수 있다.

2. Prometheus 수집
기초적인 kong 설정은 완료했기에 프로메테우스에서 수집할 대상이라는 것을 등록해주어야 한다.
방법은 아래와 같이 2가지가 존재한다.
- kong-proxy의 Deployments 객체의 Pod Template에 프로메테우스 관련 Annotation을 추가
- kong-admin이라는 Service 객체에 프로메테우스 관련 Annotation을 추가
두 가지 방법 중 편한 방법으로 아래 어노테이션을 추가해 주면 된다.
# prometheus 관련 Annotation
prometheus.io/path: /metrics
prometheus.io/port: "8001"
prometheus.io/scheme: http
prometheus.io/scrape: "true"
3. Grafana Dashboard 추가
프로메테우스 수집 대상도 설정을 했다면, Grafana에서 확인할 Dashboard를 추가해야 한다.
아래는 Grafana Labs에 등록된 공식 Kong의 대시보드 사이트다.
https://grafana.com/grafana/dashboards/7424-kong-official/
Kong (official) | Grafana Labs
Thank you! Your message has been received!
grafana.com
Kong 또한 Enterprise가 있는 제품이기에 대시보드 업데이트가 자주 있는 편은 아니다.

그라파나에서 대시보드를 불러오는 창으로 넘어가서 세 가지 중 편한 방법으로 업로드한다.
1. Grafana Labs에서 다운로드한 Json을 업로드
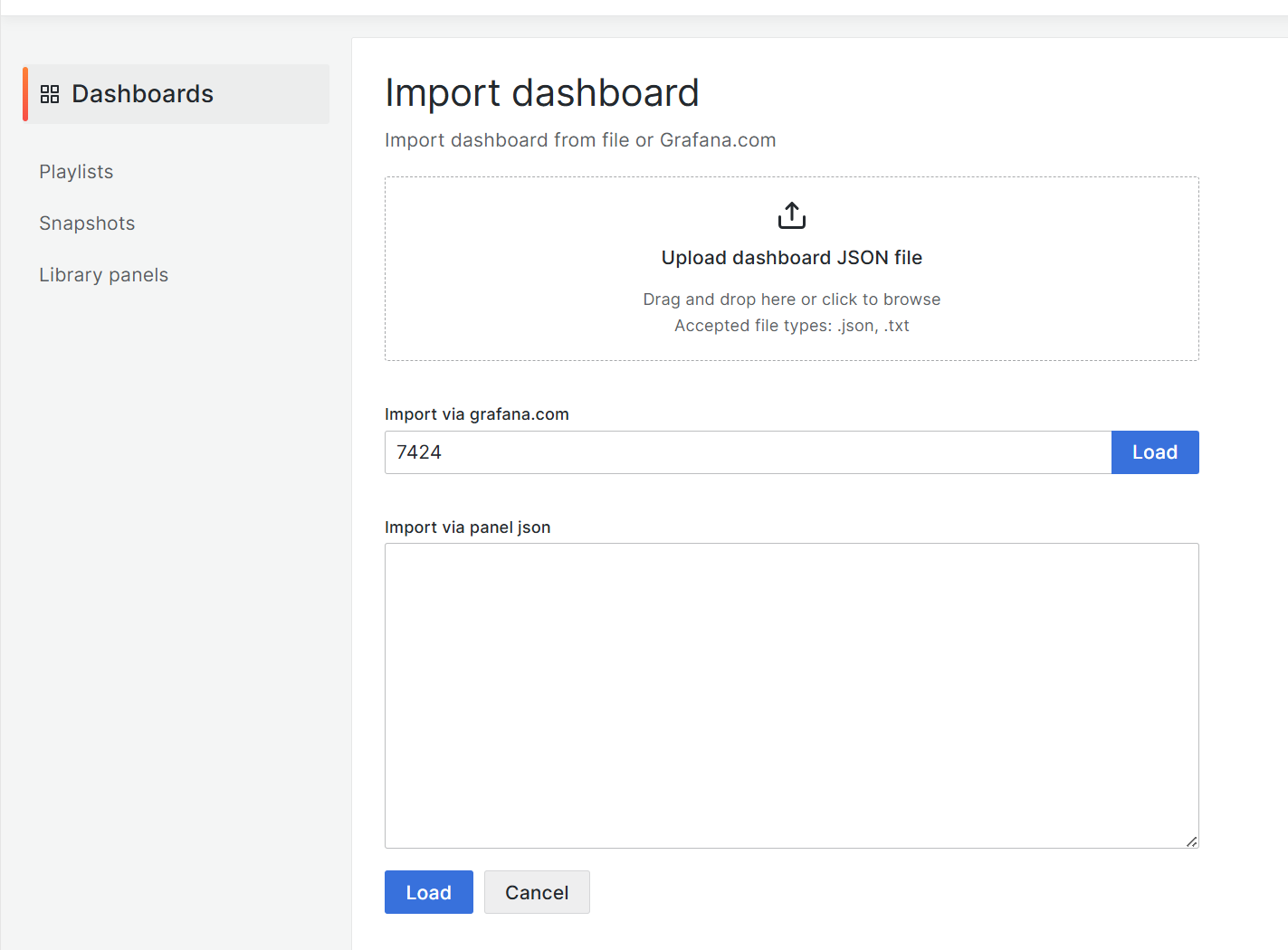
2. ID 값을 입력하여 불러오기
3. Json을 직접 입력
아래는 ID 값을 입력하는 방법을 참고하는 사진이고 ID는 7424이다.
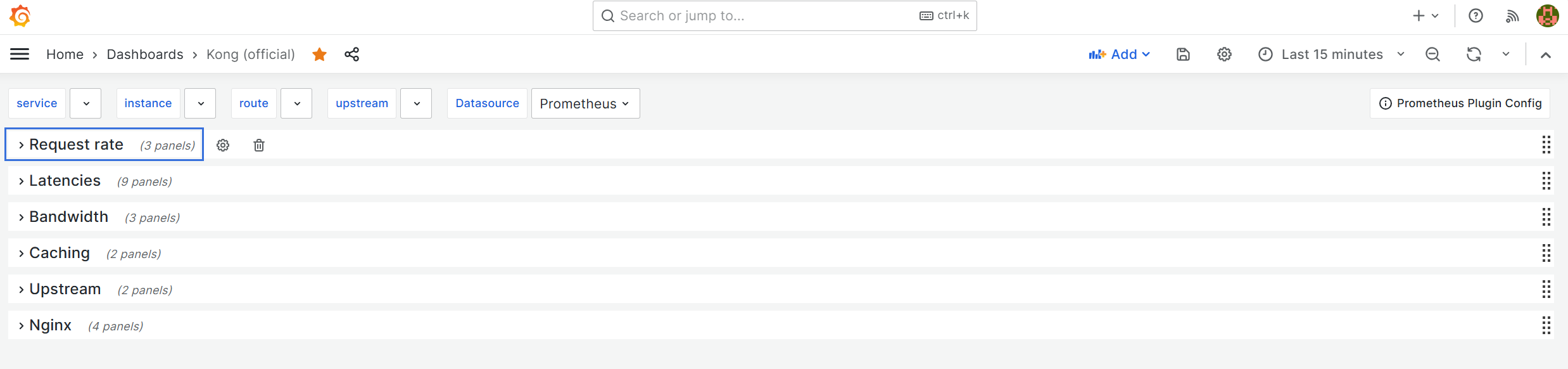
대시보드를 등록하면 아래와 같은 결과를 볼 수 있다.
하지만 Caching과 Nginx를 제외한 목록은 전부 아래와 같이 데이터가 없는 것을 확인할 수 있다.
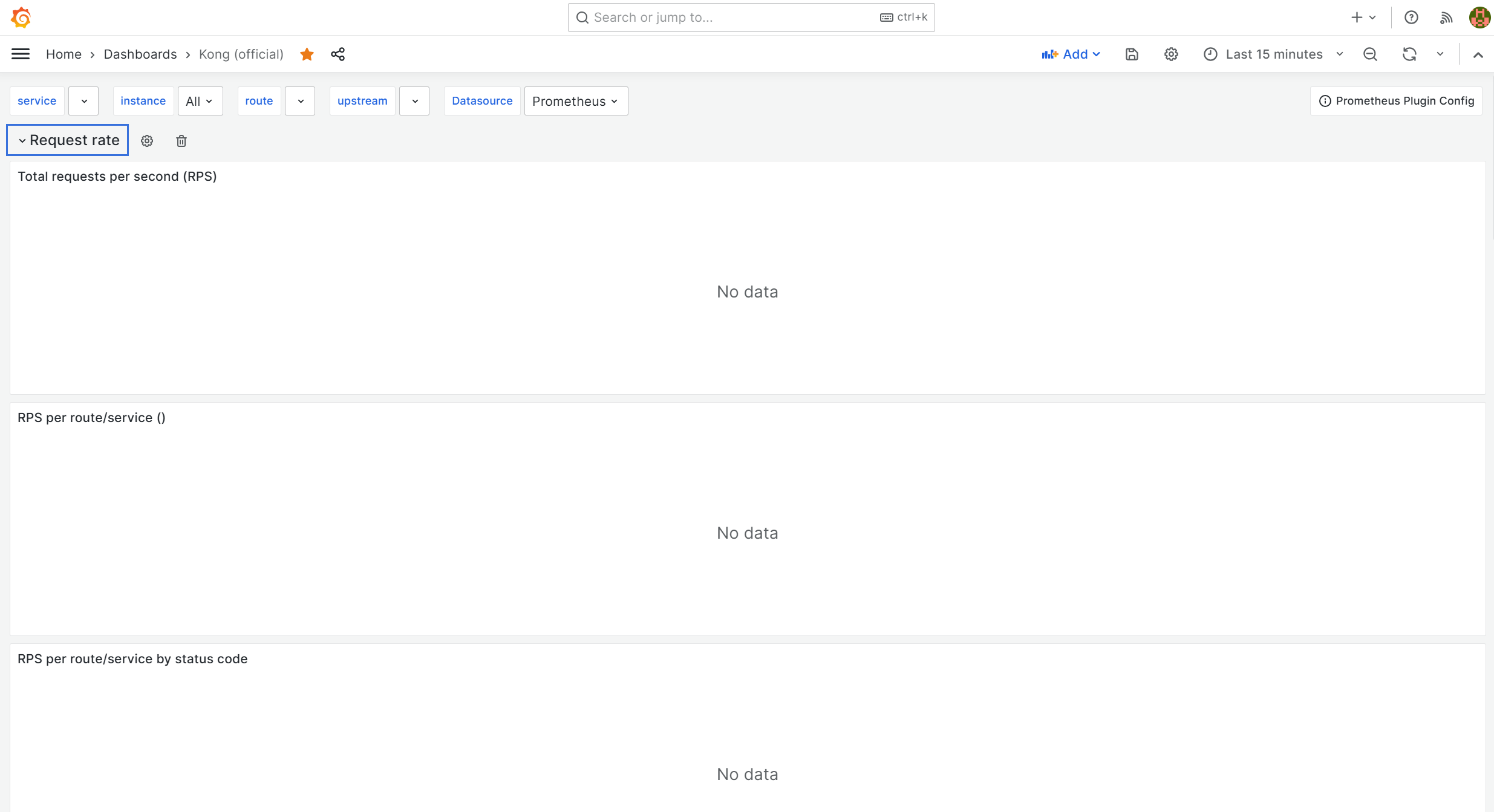
제일 중요한 Request와 Latency에 대한 정보를 알 수 없으니, 아직까지 메트릭 수집에 대한 활용을 할 수 없다는 것이다.
이는 다음 단계에서 해결할 수 있다.
4. Kong Plugin 추가
Kong Docs
Documentation for Kong, the Cloud Connectivity Company for APIs and Microservices.
docs.konghq.com
Kong의 Docs에서는 위와 같이 다양한 플러그인을 소개하고 있고, Analytics & Monitoring 부분에 Prometheus라는 플러그인이 존재하는 것을 확인할 수 있다.
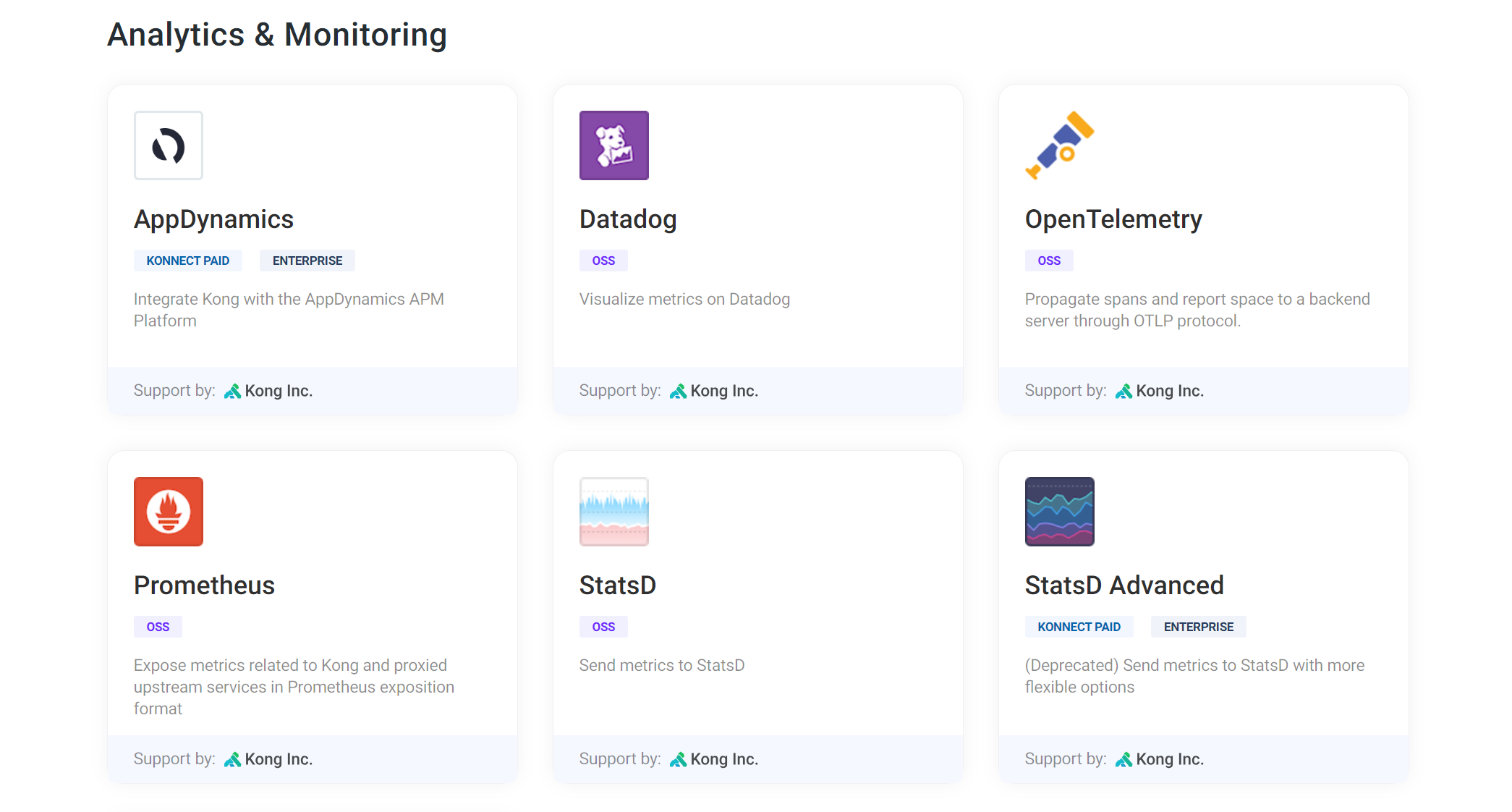
이를 보아 짐작하면, 별도의 플러그인 설정을 해주어야 한다는 것을 알 수 있다.
그리고 아래 사이트에서, 쿠버네티스 CRD를 이용하여 Kong 플러그인을 생성하는 양식을 알 수 있다.
Basic config examples for Prometheus - Plugin | Kong Docs (konghq.com)
Kong Docs
Documentation for Kong, the Cloud Connectivity Company for APIs and Microservices.
docs.konghq.com
그리고 플러그인에서 옵션으로 사용할 파라미터는 아래 사진을 참고하면 된다.
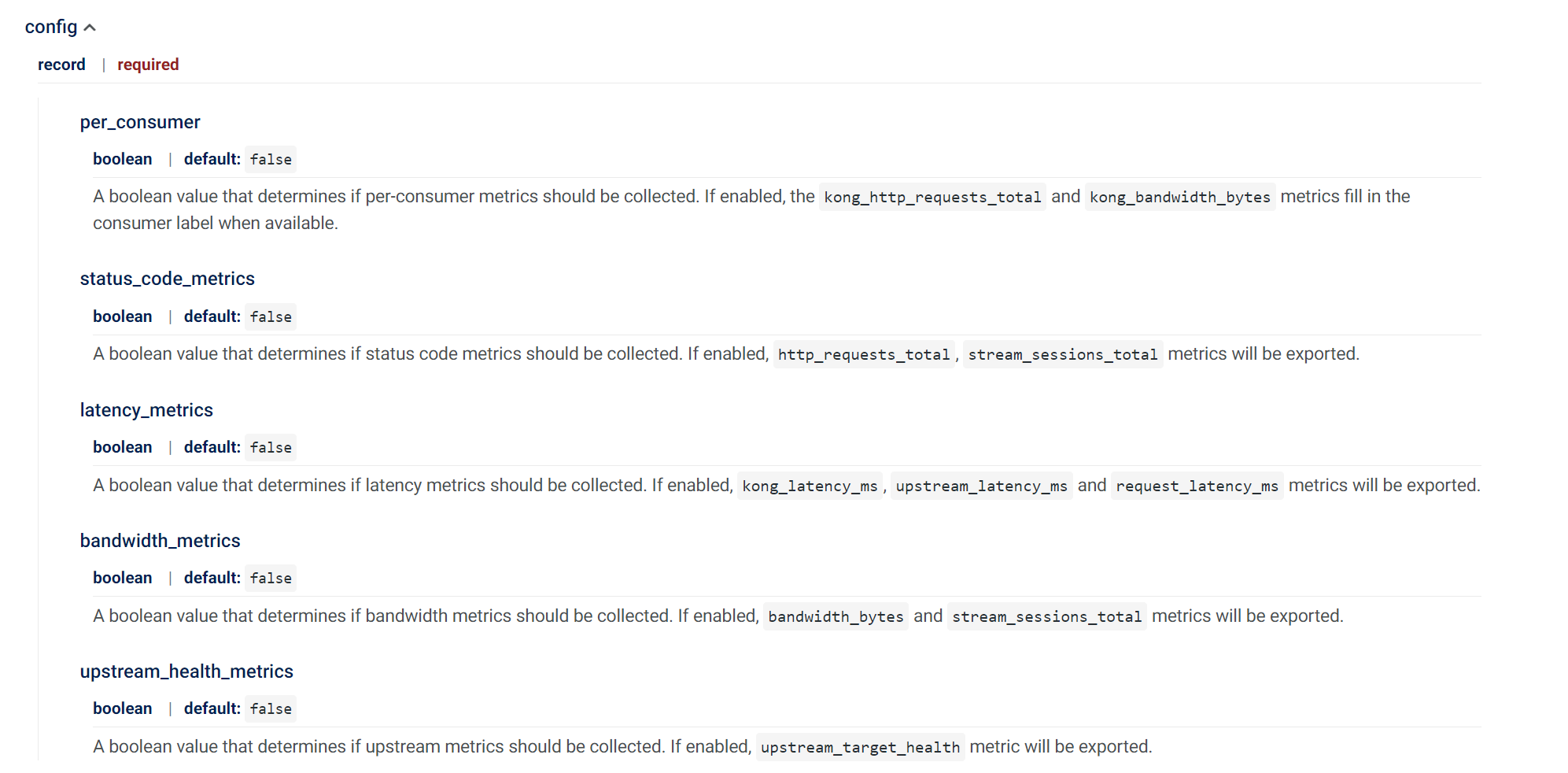
그리하여, 최종적으로 사용할 CRD의 plugin.yaml은 다음과 같다.
apiVersion: configuration.konghq.com/v1
kind: KongClusterPlugin
metadata:
name: prometheus
annotations:
kubernetes.io/ingress.class: kong
labels:
global: "true"
config:
bandwidth_metrics: true
latency_metrics: true
# consumer 미이용
per_consumer: false
status_code_metrics: true
upstream_health_metrics: true
plugin: prometheus
해당 플러그인을 생성하고 kong-proxy의 Deployments를 재시작한다.
# Deployments 재시작
kubectl rollout restart deployments [helm에 kong 배포 시 이용한 이름]-kong
일정 시간이 지난 후 그라파나 내 Kong 대시보드에 접속하면, 이전과 다르게 볼 수 없었던 데이터가 수집되고 있는 것을 확인할 수 있다.
p90/p95/p99 정보를 서비스 별 라우팅 정보와 함께 확인할 수도 있다.
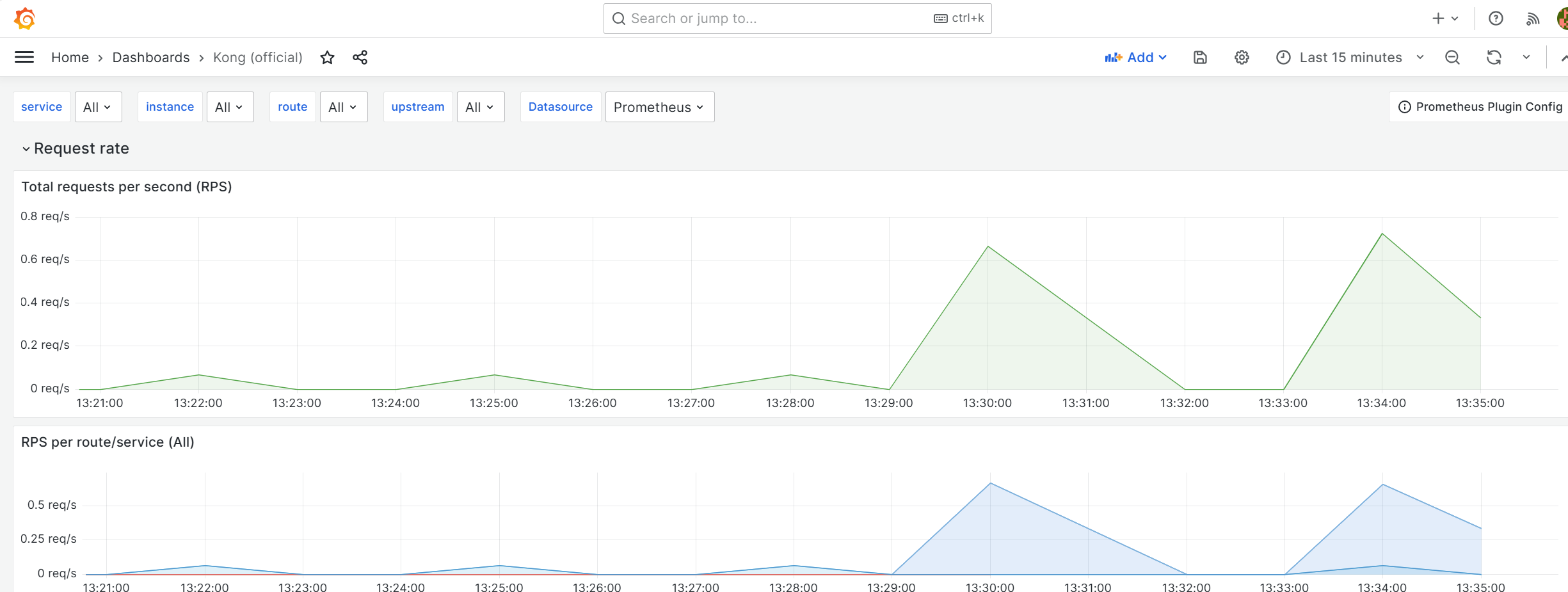

위 작업을 통하여 Ingress로 들어오는 트래픽에 대한 수집과 시각화를 할 수 있었다.
하지만 클러스터 내부의 마이크로 서비스 간의 호출과 트래픽의 흐름을 알 수는 없기에, 이를 확인하려면, 아래와 같은 별도의 Trace를 위한 솔루션이 필요하다.
[Trace Solutions]
- Jaeger
- Tempo
- Elastic Apm